








.jpg)

GDPR Ready
View report
SOC2 Ready
View report
help@latenode.com
Discord
LinkedIn
Facebook
Instagram
Youtube
Reddit
To connect GPT-4.1 and o3, you’ll use OpenAI Playground, o3’s API, and Latenode for automation. Here’s how:
Why? Automating tasks with GPT-4.1 and o3 can save time, boost productivity, and reduce costs. For example, GPT-4.1 processes o3’s project data, creates reports, or automates customer support.
Snapshot of Costs:
| Platform | Cost (per 1M tokens) |
|---|---|
| GPT-4.1 | $2.00 (input) |
| GPT-4.1 Nano | $0.10 (input) |
| o3 | $10.00 (input) |
Start with OpenAI Playground to refine prompts, then scale with Latenode for seamless integration.
To connect GPT-4.1 with o3 through Latenode, you’ll first need to set up access and API credentials for all three platforms. Each step ensures smooth integration and functionality.
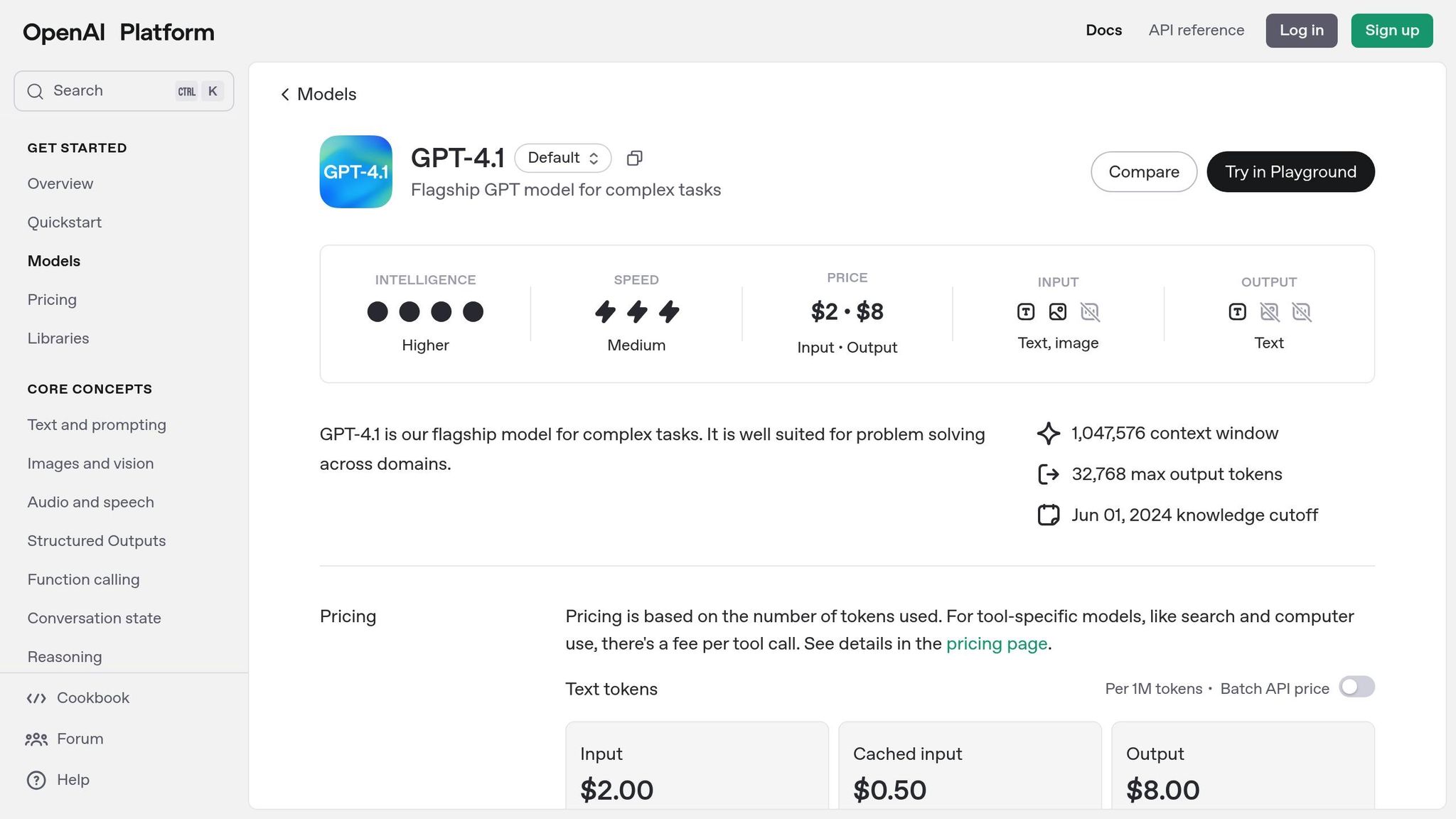
Start by obtaining API access for GPT-4.1 through OpenAI's platform. Visit platform.openai.com to sign up or log in. In the Billing section, add a minimum of $5.00 to avoid service interruptions [2][3].
Next, navigate to the API Keys section to create your credentials. Generate a new API key and give it a clear, descriptive name, such as "Latenode-o3-Integration", for easy identification later [2]. Make sure to store this key securely, as it will only be shown once.
The GPT-4.1 API pricing is straightforward: $2.00 per 1 million input tokens and $0.50 per 1 million cached input tokens [2]. For production environments, OpenAI recommends logging request IDs to simplify troubleshooting [1].
To integrate project data with GPT-4.1, you’ll need an o3 account. Register on the AI/ML API platform, verify your account, and then visit the Key Management section to create an API key specifically for GPT-4.1 integration [4].
The o3-mini model offers powerful automation options, including the ability to choose between low, medium, and high reasoning effort levels. This flexibility allows you to tailor performance to your specific automation needs [5].
It’s important to note that OpenAI’s reasoning models, such as o3-mini, may require additional configuration and could have limitations when using certain custom API key setups [6]. To ensure proper integration, follow the platform's API reference documentation carefully [4].
Latenode acts as the central hub, orchestrating workflows between GPT-4.1 and o3. It features a visual workflow builder combined with support for custom code and AI-driven logic. With connections to over 300 apps, Latenode provides the tools needed for even the most complex automation scenarios.
Begin by creating a Latenode account and choosing a plan that aligns with your requirements. The Start plan, priced at $17 per month, includes 10,000 execution credits and supports up to 40 active workflows. If you need more capacity, consider upgrading to the Grow plan.
Within Latenode, configure connections to OpenAI and o3 using the API keys you generated earlier. The platform’s AI-native features enable seamless integration with OpenAI models, while its built-in database tools allow you to store and manage data from o3 workflows effectively.
With your API credentials ready, you’re now set to connect these platforms and move on to building your automation workflows.
Once you've secured your API credentials, the next step is setting up communication between GPT-4.1 and o3 by configuring the appropriate endpoints and authentication headers.
The OpenAI API relies on HTTP Bearer tokens for authentication and uses a consistent base URL structure. Start by setting your API endpoint to https://api.openai.com/v1, which serves as the foundation for all requests.
In Latenode, use the HTTP node to configure your headers. Add an Authorization header with the value Bearer YOUR_API_KEY, replacing YOUR_API_KEY with the API key from your OpenAI account. This single API key can be used across various OpenAI models, including GPT-3.5 Turbo, GPT-4, and DALL-E.
For GPT-4.1 responses, use the endpoint POST https://api.openai.com/v1/responses. Your request body should include the model parameter (set to gpt-4.1), the input parameter with your text or data, and optional parameters like temperature or maximum tokens. To ensure security, store your API key using Latenode's credential management system instead of embedding it directly into workflows.
After configuring GPT-4.1, follow a similar process to integrate the o3 API. Before accessing the o3 API, verify your organization - a process that typically takes around 15 minutes [7]. Once verified, create a separate HTTP node in Latenode for your o3 API calls.
Set up the o3 API headers using the key generated during your account setup. Unlike OpenAI, o3 may use a different authentication method, so consult their API reference documentation for precise details. Make sure to include any required parameters, such as the model identifier, in your request body as specified by the o3 documentation.
Before diving into complex workflows, it's crucial to confirm that your API connections are working as expected. The Responses API is particularly useful for testing and can be paired with remote Model Context Protocol (MCP) servers for extended functionality [10].
Start by sending a simple "Hello, world!" message to GPT-4.1 and a similar test request to o3. Use Latenode's logging features to monitor the data flow and ensure both APIs are configured correctly. For a more thorough test, build a workflow in Latenode that transfers data from o3 to GPT-4.1 - such as having o3 generate data that GPT-4.1 then processes or formats.
For production use, consider implementing request ID logging to simplify troubleshooting. Latenode's execution history feature automatically tracks these details, making it easier to pinpoint and resolve connectivity issues. Once verified, these connections lay the groundwork for building efficient and reliable workflows in Latenode.
Latenode's visual builder simplifies API integrations by transforming them into intuitive drag-and-drop workflows. This approach makes it easy to create seamless automations involving GPT-4.1 and o3. Below is a guide to help you build and refine your workflow step by step.
To start building your workflow, use Latenode's visual interface, where each step in the automation is represented as a connected node. Begin by creating a new workflow and adding a Trigger node. This trigger could be a webhook, a scheduled timer, or even a manual action, depending on your specific needs.
Once the trigger is in place, incorporate preconfigured HTTP nodes for API integration. These nodes allow you to connect with GPT-4.1 and o3 APIs effortlessly. Typically, o3 generates the initial data, which GPT-4.1 then processes or enhances. Use the drag-and-drop feature to connect the nodes, defining the flow of data between them.
For workflows that require handling varied responses, use Conditional Logic nodes. For example, if o3 returns data in multiple formats, you can route each format to the appropriate GPT-4.1 processing nodes. This flexibility ensures your workflow can adapt to real-time variations in API outputs.
Latenode supports over 300 app integrations, making it easy to extend your workflow. For instance, you can store processed data in Google Sheets or send notifications via Slack. These integrations are available as pre-built nodes, saving you the effort of manually configuring additional API endpoints.
To configure inputs for GPT-4.1, map the outputs from o3 while ensuring your prompts remain clear and within token limits. Latenode uses a variable system with double curly braces {{variable_name}} to reference data from earlier nodes.
Before sending data to GPT-4.1, consider using Text Processing nodes to clean or format the information. This preprocessing step ensures consistency and minimizes the chance of errors during API calls.
You can also configure multiple output paths to enhance your workflow's efficiency. For example, format data for storage in Google Sheets while simultaneously sending summaries to team communication tools like Slack. Use the double curly brace notation to map o3 outputs to GPT-4.1 inputs and validate data formats using custom JavaScript if needed.
Effective error handling is essential for maintaining a reliable workflow. After mapping your data, prepare for potential issues like rate limits, timeout errors, or authentication failures. Latenode provides built-in tools to address these challenges.
Add Try-Catch blocks around API calls to manage errors without disrupting the entire workflow. For temporary issues, configure retry logic with exponential backoff. This is particularly useful for GPT-4.1, which may experience higher demand during peak times. With Latenode, you can define retry attempts, delays, and specific conditions that trigger retries.
To monitor and optimize your workflow, use Latenode's execution history feature. This tool logs details such as execution times, error messages, and data flow for every workflow run. These insights are invaluable for identifying bottlenecks and troubleshooting unexpected behavior.
Incorporate Log nodes at critical points in your workflow to capture variable states, API response codes, and processing times. This creates a detailed audit trail that simplifies debugging. Additionally, configure notifications via Slack or email to alert you of specific error conditions, allowing for a quick response to issues.
For added reliability, consider creating separate error-handling workflows. These workflows can activate if the primary process encounters issues, implementing alternative methods, notifying team members, or storing failed requests for later review. This proactive approach ensures smooth interaction between GPT-4.1 and o3, even when challenges arise.
Building on the integration discussed earlier, these examples highlight how combining GPT-4.1 with o3 can address practical challenges across content creation, customer support, and data management. Together, they simplify workflows and bring efficiency to tasks that typically require significant time and effort.
For content teams, pairing o3's analytical capabilities with GPT-4.1's writing skills creates a powerful workflow. o3 takes care of the heavy lifting - researching market trends, analyzing competitor activities, and gathering audience insights - while GPT-4.1 focuses on producing well-structured, polished content. This partnership not only saves time but also ensures consistent quality.
With Latenode, you can automate the entire process. Data from o3 flows seamlessly into GPT-4.1, which then generates content that can be directly integrated into tools for managing content calendars. Whether it's blog posts, social media updates, or marketing materials, GPT-4.1's ability to follow instructions reduces the need for revisions, ensuring a smoother workflow.
Customer service provides a clear example of how GPT-4.1 and o3 can transform operations. GPT-4.1 powers chatbots capable of handling customer queries by drawing from FAQs and product databases. These bots can retrieve detailed product information instantly, ensuring faster and more accurate responses to common questions [11].
When it comes to more complex issues, o3 steps in to analyze error logs, system settings, and historical data to pinpoint problems. GPT-4.1 then translates these technical findings into clear, customer-friendly responses.
An inspiring example comes from CodeRabbit, which uses this integration in its code review tool. o3 tackles complex tasks like identifying multi-line bugs and refactoring code, while GPT-4.1 summarizes reviews and performs routine quality checks. Since implementing this system, CodeRabbit has seen a 50% improvement in accurate suggestions, better pull request merge rates, and higher customer satisfaction [13].
"We think of CodeRabbit as a senior engineer embedded in your workflow. It's not just AI that reviews code. It's a system that understands your codebase, your team's habits, and your standards - powered by models with the reasoning depth to catch real issues." – Sahil M. Bansal, Senior Product Manager at CodeRabbit [13]
Latenode plays a crucial role here, seamlessly coordinating the process from customer inquiries to issue resolution and team notifications.
This integration also shines in data-heavy tasks. Businesses handling large, complex datasets can benefit from o3's analytical strength paired with GPT-4.1's ability to produce clear, professional reports. o3 processes data, identifies trends, and summarizes findings more efficiently than traditional methods, allowing organizations to adapt strategies faster [12]. Additionally, o3 can autonomously decide when to utilize tools like Python scripts or web searches to validate its results [12].
In industries like financial services, this combination is particularly effective. o3's analytical depth supports tasks such as research, development, and compliance, while GPT-4.1 ensures that the final reports are well-organized and require minimal editing. This approach not only saves time but also enhances the accuracy of financial documents and compliance reports [14].
Using Latenode, these processes are fully automated - from connecting to databases and analyzing data to generating reports and distributing them to stakeholders. GPT-4.1's enhanced capabilities often mean fewer API calls, streamlining even the most complex analytical workflows.
Improving integration performance not only helps lower expenses but also ensures smoother workflows, especially when using tools like Latenode. Achieving efficiency at scale involves refining API calls, managing context effectively, and implementing cost-control strategies.
Optimizing API calls is a critical step in maintaining performance. By caching responses, you can eliminate up to 98.5% of redundant requests, saving both time and resources[15]. Connection pooling, which keeps database connections open, significantly cuts down processing time. Additionally, asynchronous logging speeds up operations, offering noticeable performance gains[15].
To improve network performance, focus on minimizing payload sizes through methods like pagination or compression. When updating data, opt for PATCH requests instead of sending entire datasets[15]. For workflows in Latenode that connect GPT-4.1 and o3, you can enable connection pooling and caching directly within HTTP nodes. Prompt caching, in particular, reduces latency and costs for GPT-4.1 by leveraging discounts on repeated queries[8].
GPT-4.1 provides a massive 1 million token context window, but performance can suffer with extremely large inputs. For instance, accuracy may decline from 84% at 8,000 tokens to just 50% when using the full context window[20][21]. To maintain optimal performance, craft clear, concise prompts and position critical instructions at both the beginning and end of your input[17]. Utilize the tools field for defining functions instead of manually inserting descriptions[19].
A multi-model approach can also enhance efficiency. As Remis Haroon aptly states, "Each model is a tool, not a tier. Choose it like you'd choose a wrench or a scalpel"[16]. For example, you might use a smaller model for initial triage before passing complex tasks to GPT-4.1. GPT-4.1 Nano, for instance, is capable of returning the first token in under five seconds for queries involving 128,000 input tokens[8].
| Model | Input Cost | Output Cost | Best Use Cases |
|---|---|---|---|
| GPT-4.1 | $2.00/1M tokens | $8.00/1M tokens | Complex coding, production workflows |
| GPT-4.1 Mini | $0.40/1M tokens | $1.60/1M tokens | High-volume, cost-sensitive applications |
| GPT-4.1 Nano | $0.10/1M tokens | $0.40/1M tokens | Classification, autocomplete, low-latency tasks |
Keeping costs under control starts with monitoring API usage. Tools like OpenAI's dashboard and the tiktoken package are invaluable for tracking token consumption[22]. Caching and batching requests can reduce token costs by as much as 50%[22]. Pre-filtering inputs using embedding or judgment-based methods can further cut token usage by 30–50%, all while maintaining output quality[22][23].
When working on tasks like classification or data extraction, structuring outputs to use fewer tokens can make a big difference. For instance, a project using GPT-4.1 Mini processed 20 queries while generating only 24 output tokens[22]. Setting rate limits - such as tokens per minute (TPM) or requests per day (RPD) - can also help prevent unexpected cost overruns[23].
For integrations with o3, be mindful of its pricing: $10 per million input tokens and $40 per million output tokens. If cost is a concern, consider o4-mini, which charges $1.10 per million input tokens and $4.40 per million output tokens[18]. Within Latenode, you can create monitoring workflows to track API usage across GPT-4.1 and o3. Set alerts to notify you when spending approaches predefined thresholds, ensuring you stay within budget while still achieving efficient and streamlined workflows.
Connecting GPT-4.1 with o3 through OpenAI Playground unlocks the potential for automating intricate workflows. While the process involves technical steps, following a structured approach - from securing API access to optimizing for cost - makes the integration both achievable and impactful.
The real power lies in moving beyond basic connections to design intelligent workflows, especially with tools like Latenode. Users have shared experiences of enhanced task accuracy, faster development timelines, and fewer production errors, highlighting the practical benefits of integrating advanced AI models into everyday solutions. By building on the initial setup steps, you can explore more advanced automation possibilities using Latenode.
To maximize the value of these models, focus on mastering API implementation. Begin with simple experiments in the OpenAI Playground to refine prompts and parameters, then scale up to more complex automations within Latenode. Workshops on advanced prompting techniques and API usage for GPT-4.1 and o3 can also provide valuable insights. As OpenAI notes, “Prompt engineering is a core part of API success. Strong prompts lead to better, more predictable outputs” [9]. This underscores the importance of crafting effective prompts for consistent results.
Additionally, the pricing model allows for a balanced approach, ensuring cost-efficiency without sacrificing performance. Fine-tuning GPT-4.1 mini can further enhance accuracy while minimizing the need for extensive post-processing [24], making it a smart choice for initial automation projects.
To safeguard your API keys during integration, consider these key practices to maintain security:
By following these practices, you can better protect your API keys and maintain the integrity of your workflows.
By integrating GPT-4.1 with o3, you open up opportunities to automate tasks that can significantly boost efficiency and simplify operations. For instance, it enables you to coordinate intricate API requests to fetch data from various platforms, streamline customer support activities such as ticket sorting and automated replies, and even create tailored scripts or code snippets for technical initiatives.
These automation capabilities are especially valuable for organizations aiming to reduce time spent on repetitive duties, enhance precision in data processing, or develop flexible low-code solutions designed to meet specific business requirements.
Managing expenses while leveraging GPT-4.1 and o3 for automation requires a thoughtful approach. Here are some practical ways to keep costs under control:
By applying these strategies, you can balance cost-efficiency with performance, ensuring your workflows remain both impactful and budget-friendly.


Swap Apps
Application 1
Application 2
Step 1: Choose a Trigger
Step 2: Choose an Action

No credit card needed
Without restriction










